Linux IP Stacks Commentary WebEdition
Routing
Communicating over a network means sending data from one computer to another. This sounds simple, and it is...when only two computers are involved...when those two computers are alike...when those two computers are physically near one another...and especially when the equipment doesn’t fail.
Alas, few if any of these conditions are present on the Internet. Indeed, when an individual user of the Internet communicates with a popular server, the connection can involve dozens of intermediate computers, each with its own name and IP address, and designated duration. If you’re curious about the number, you can use the traceroute(1) utility on your Linux computer (or the tracert program in a DOS window on a Microsoft system) to find out exactly how many other systems lie between you and a given destination site.
The traceroute utility uses the Internet Control Message Protocol (ICMP) facility of the Internet Protocol (IP) to determine how packets are transferred through the network, and to measure the transmission time required for each step of the journey.
For example, we often communicate with www.linux.org, starting from our connection to AT&T’s fiber center. The following report (produced by the traceroute program) shows the path followed by our data packets, and the stops our packets make along that path, during their journey from our office to the server that hosts the Linux Home Page:
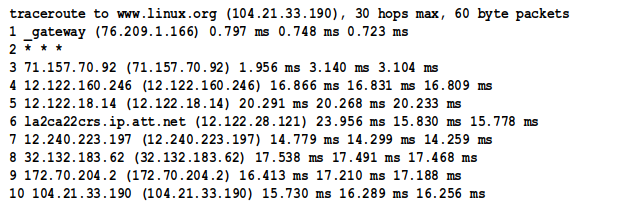
The above report tells us that our data packets made 10 hops, starting at the fiber interface in our office and ending at the web server. For each of the 10 hops, the report gives us: (1) the domain name (if available) and the IP address of each of those nodes; (2) the round-trip duration (in milliseconds) of each of the three probes that the traceroute program sends to each node in the series.
Where did this arrangement come from, and why is it so complex? To answer these questions, we need to take a brief look at the history of distributed network computing.
The granddaddy of today’s Internet was an experimental communications system — the Advanced Research Projects Agency Network, or ARPAnet — conceived in the 1960s at the RAND Corporation on behalf of the U. S. Department of Defense (DOD). It launched in 1971 with four sites in the western United States. By 1976, the projected number of nodes in the ARPAnet had grown to an unmanageable figure (255, to be precise), and a new way to connect them had to be found. Enter the router, which enabled the ARPAnet to double in size over the next few years, acquiring 200 host machines by 1981. In 1985, the ARPAnet broke the thousand-host barrier. By 1989, the experiment was over, and the ARPAnet as a system ceased to exist...leaving more than 100,000 machines interconnected via something called the “Internet.”
Because of the circumstances envisioned for its use, the ARPAnet was required to heal itself whenever any single part of the network failed. One type of failure contemplated by the DOD was the physical destruction of the ARPAnet’s computers and communications links by “nuclear events.” This requirement set the ARPAnet apart from the commercial computer networks of the day, which were centrally controlled. To prevent a single point of failure from bringing down the entire communications system, the ARPAnet’s controlling functions had to be distributed, as evenly as possible, among locations physically located many miles apart.
Obviously, the number of possible failure points was huge. Moreover, because any given computer could, in theory, fail at any given time, the ARPAnet’s designers also faced the daunting task of dealing with random changes in the topology of the network. These changes, the designers theorized, would be caused by nodes and links that not only disappeared, but, in the fashion of some subatomic particles, also appeared utterly unexpectedly and unpredictably — which, as it turned out, is exactly what happened during its lifetime.
The ARPAnet’s protocol design was continually revised, based on an analysis of the hardware, telecommunications, and software failures that occurred. The changes that were made allowed the ARPAnet to cope with most failures automatically, finding alternate routes to keep data flowing even if several nodes or links went down. These workarounds are still part of the Internet today.
Here’s how the ARPAnet’s workarounds worked. Each connection node on the network, known as an interface message processor (IMP), kept a living record of neighboring nodes and traded information with those nodes at regular intervals. The sum of each IMP’s knowledge — including the list of neighboring nodes and a history of the information exchanged with those nodes — was stored in a dynamic structure known as a routing table. (Routing tables are still present, playing a more important role than ever, in today’s Internet hosts. Entire books have been written about their design and use, and an in-depth discussion is beyond the scope of this book.)
From a cold standing start, all the nodes on the ARPAnet needed only a few minutes to learn enough about the network’s topology to be able to send data to the proper destination. As the nodes built a history and exchanged data with each other, they “learned” the best data-transmission routes. In less than an hour, the nodes learned so much about ARPAnet routing that, when a glitch occurred (and glitches could range from a momentary interruption of transmission to the complete shutdown of a node), users rarely noticed it.
This learn-as-you-go technique is what the Internet uses today. As an example, consider how this technique helps your data get from your machine to a server located 12,000 miles away.
Before any data goes anywhere, it has to be properly “gift-wrapped.” In the Internet, the bow-adorned object is an IP packet, which consists of (1) a digital box with data inside, (2) wrapping paper to ensure that the data stays together, and (3) a label that states who is sending the packet and who is supposed to receive it. Unlike the typical recipient of a holiday gift, the intended recipient of an IP packet can be miles or continents away...and the IP label tells you absolutely nothing about how to get the package to the right tree.
In a well-known experiment done in the 1960s, researchers found that a letter, addressed (by name only) to a randomly selected individual and entrusted to another randomly selected individual, reached the addressee after a remarkably small number of person-to-person transfers. (In fact, the researchers concluded that any living person could theoretically reach any other living person in six or fewer “hops.”) The purpose of the experiment was to show how many people each human being knows directly and, by concatenation and extension, how interconnected all of humanity is.
However, computers aren’t people, so the designers of the ARPAnet had to devise a less complex way to accomplish the same task; that is, determining a path between two random points without the help of a master directory. When the ARPAnet was small (with fewer than 64 nodes), each IMP kept a record of how far away and in what (logical) direction each host was located. As the ARPAnet evolved toward the Internet, network designers started to group hosts together, into subnets, to limit the amount of record-keeping data to a manageable size. Thanks to subnets, the amount of data that a pair of routers had to transfer to one another was also kept to a reasonable size. Today’s Internet routers still operate this way, working in layers, so that each router’s task is relatively small — even if the number of hosts exceeds a billion. “Divide and conquer” could well be the Internet’s motto.
At its most elementary level, routing function means switching data through a series of interconnected devices, so that the data gets from its source to its destination. First, some backstory:
Every single node connected to the Internet performs this TCP/IP routing function, whether it’s your phone, laptop, desktop computer, Internet-connected device...or a special-purpose computer which is referred to by network engineers as, naturally enough, a router. Whatever else is happening in the node, there are at least two network interfaces sending and receiving data: the loopback which is what the computer does to exchange data within itself and the world, and at least one connection to the network. When we say “at least”, the upper limit can be far, far higher. The interfaces can be RS-232, V.35, T1, E1, T3, E3, DS3, high speed serial interfaces, fiber, various multiplexing schemes over physical interfaces, and more. Even carrier pigeons (RFC 1149).
Figure 1 shows a simplified view of the interconnections in the Internet. The blue cylinders with the four arrows on the top is the network schematic symbol for a router. The lines represent connections, which can be wire, coax, fiber, radio, or satellite links. The wireless router (access point) in your home is considered customer gear in this diagram, but it’s also a form of access service in its own right. (I told you this view is simplified.)
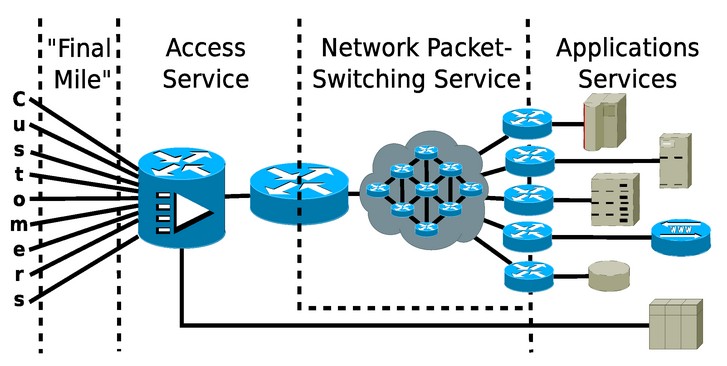
Figure 1 Organization of the Internet
How does this router work? Let us use as an example a router with nine interfaces. A packet comes in on one of the interfaces. The routing software determines the incoming packet’s destination address and, using the information stored in the router’s internal routing table, determines the best interface to use to send out the packet. The routing table’s design incorporates the concept of a default route, which is “an interface of last resort”. In your computer, this is referred to as the gateway address; with only one connection to the outside, your computer sends all packets through that interface.
Or to no interface at all. The routing table allows entries that say “if you see this destination in a packet, discard it.” (Cisco calls this the null interface.) The routing software removes the packet from a router’s memory, in an operation known familiarly as “sending the data to the bit-bucket.”
(Administrative blocking of packets is discussed in the section Firewall Support)
A router follows the same steps each time it performs the analysis and interface-assignment process on an incoming packet. So, why doesn’t the router always send out data packets via the same interface? Because the interface that the router ultimately selects depends on the information stored in the router’s routing table at the time, not on any change in the way the router performs its analysis of that information.
In short, then, the act of routing embraces the entire process of getting a message from, for example, the small (and very real) town of Truth or Consequences, New Mexico to its ultimate destination, the capital city of Ouagadougou, in the African nation of Burkina Faso.
The router code that is the subject of this chapter uses information about the network (as collected by the IP and ICMP protocol handlers, and by other node-resident processes that exchange information with neighboring nodes) to decide how to forward a data packet. However, in the router world, a data packet’s destination is not necessarily a physically different machine. An internal process within a router is just as valid as an external destination, and routers often “send” packets to such internal processes. (In the simplest case, the software in the computer can literally talk to itself.)
Initially, the routing table is populated with information contained in the configuration of the interfaces in the router. This is the initial routing table from one of my servers:

(My LAN defines a VLAN, vlan2; in Linux each VLAN shows up as a separate interface.)
The routing table is then kept up-to-date by a set of pick-a-little talk-a-little router-to-router protocols. These protocols, which are implemented within daemons (programs that live in the computer, but that are not part of the kernel), gossip continually with each other. By exchanging information this way, and especially by discarding obsolete information about traffic conditions and external nodes, they make the kernel code’s task much easier. The kernel code, which uses the routing table several hundred times a second when data is being transferred, is appropriately grateful.
Back to your gift-wrapped data package. The IP packet starts out in your computer from its point of origin in Truth or Consequences, New Mexico. The first router, the ISP router, contains a collection of hints in its routing table, gathered from its neighboring routers, that suggests the best way to forward a packet toward Ouagadougou. In the data-transmission world, “best way” may mean any of several things. It might be either the fastest way to send information, the method that’s cheapest in terms of resources or money, the route that’s the least sensitive politically, or the pathway that’s the least likely to damage the data. When all else fails, there is a default route that causes the router to “pass the buck” to another router — this is how your desktop, laptop, table, or phone knows how to send off data not intended for itself.
The first router sends your package to a second router, which, with luck, is located well toward your package’s destination. This second router then makes its best guess about how to pass the data, and speeds the package on its way toward the next router. The process continues until the package reaches its destination in Ouagadougou and the recipient opens it. In the very worst case, the package never gets to Ouagadougou. Instead, it hits a digital dead-end and is dumped unceremoniously into a bit-bucket.
In an ideal world, your package would travel as directly as possible to its destination. However, the data-transmission world is far from ideal. Just as on city streets or at airports, traffic congestion can affect a router’s forwarding decision, such that packages are sent on detours around the slow or stacked-up areas. Quite conceivably, your Africa-bound package could arrive in New York City or Casablanca, only to be turned around and routed back westward.
Or not. Sometimes, a router doesn’t know that a path is congested, and forwards an IP packet into a gridlock anyway. Remember, in selecting the outgoing path for a packet, a router bases its decision on the information it obtains from neighboring routers. When traffic conditions change, routers have no way of learning about the changes instantaneously. It takes time for the word to propagate outward from a congested node or link, and, in the meantime, a packet could arrive at a router and be sent onward, in all innocence, into trouble.
At its most frustrating, this slow spread of information among routers can cause an IP packet to travel in circles — in other words, in an endless loop. An endlessly looping packet eventually self-destructs, dying of old age. Unlike the United States Postal Service, the Internet has no Dead Letter Office for defunct datagrams. Instead, looping IP packets evaporate without a trace, considerately relieving the Internet of the need to dispose of them.
This wasn’t always the case. In the early 1970s, the ARPAnet was sometimes very, very busy, but no data was getting through to users. The activity level was caused by packets that had invalid host addresses and therefore stayed alive — and undelivered — indefinitely in the network, like a subway passenger caught short by a fare increase, doomed to ride forever beneath the streets of Boston — the datagram that never returned. That’s when the network designers gave packets a finite lifespan.
The routing tables are implemented in Linux as linked lists. Although the tables are updated once or twice a minute, they are referenced many, many times — on a busy system, hundreds or even thousands of times per second — by routing protocols, by certain free-running processes, and, most frequently of all, by the IP module in the kernel code.
The IP module’s job is to handle packet routing requests. Each packet is associated with its own routing request, which means that the IP module may have to process as many as 150,000 requests per second. Unfortunately, one routing request does not necessarily imply only one pass through the routing table. To handle a single routing request, for a single packet, the IP module may need to make several trips through the routing table. First, it looks for a specific host entry. If the host entry appears in the routing table, the IP module uses the designated port associated with that host. If the desired host doesn’t appear in the list, then the IP module searches for the addresses of a subnet that contains the host. If the IP module does find such a subnet, it sends the data out through the designated port for that subnet. If it doesn’t find the right subnet, then it looks for a default port to which to send the data. If it finds the wild-card address of a default port, it sends the data to that port. Otherwise, it returns an error message and takes the appropriate action, depending on the source of the routing request.
To recap, based on the information stored in the routing table, a data packet is directed to a specific interface on the computer to be sent out. In the trivial case (when a router box has only one outgoing port), the packet is sent to a port (such as a modem or an Ethernet port) that leads to the outside world. When a router has two or more ports to the outside world, the decision process becomes more complex, but the result is the same: the IP module decides which port gets to send the packet.
For an idea of the amount of work a router does, consider a digital DS3 trunk operating at a speed of 44 megabits/second (Mbps). A router connected to such a trunk handles from 60,000 to 150,000 packets per second, virtually nonstop in a Web hosting company. In other words, this router has six whole microseconds (0.000006 second) to redirect each packet that comes in through any single port. If the redirection takes longer, the whole stream of packets may slow down, or even stop.
A T1 or ADSL (asymmetric digital subscriber line) channel is much slower, pouring in only 2,000 to 5,300 packets/second, whereas a 56-kilobyte/s (Kbps) modem or frame relay connection drizzles just 75 to 180 packets/second into the router. But no matter how fast or slowly the packets come in, the time required to make a routing decision directly affects a router’s performance, even if the router lives in a single system. Indeed, packets can be lost when input buffers overflow, which can happen when a router’s decisions are too slow. Fortunately, as you’ll see in the commentary section of this chapter, the Linux code contains some time-saving tricks that keep the routing process from becoming a data bottleneck.
Messages travel through the Internet much the same way that checks flow through the commercial banking system. From the bottom up:
Individual Internet surfers are analogous to businesses depositing checks that they’ve received from customers.
Companies whose networks are completely internal (the intranets, used only by company employees and authorized guests) are analogous to small banks.
A typical regional ISP is analogous to a standard bank.
The upstream providers are analogous to bigger banks.
The Internet has several nationwide ISPs, each with its own network, which are analogous to the multi-state megabanks.
At the very top of the heap, the similarity diverges slightly. Instead of a single analog of the U. S. Federal Reserve System, the Internet has several backbone providers, in the form of the companies who run the large networks that link the various regions of the United States and the world. However, like the Fed, these companies are the lords of all they survey.
Checks fly in and out of banks in all directions. A few checks are deposited at a bank against accounts at that same bank—that’s the easy case and is handled completely in-house. The vast majority of checks, though, are drawn on one bank and deposited at another. They come in through teller windows and ATM machines; from correspondent banks; and (for member banks) from the Fed itself. The incoming checks drawn on accounts at the bank itself are separated and processed, and then the checks drawn on other banks are sorted and sent on their way.
Analogously, data packets fly in and out of IP routers through a number of ports. When you log on to the Internet, your system receives packets confirming or denying your access. Those packets are sent to, and stay in, processes that live in your computer system. However, the great majority of packets that are sent out from your computer, via your modem or broadband link to the Internet, are processed at another system — usually a server of some kind — living at your ISP. A router box located at your ISP, at the upstream provider, or in the backbone can, in theory, have as few as three ports; however, most of these routers have several hundred ports through which incoming packets arrive and reshuffled packets depart.
What makes the check-clearing analogy to the Internet so remarkable: the decisions that govern how checks are routed are exactly the same decisions that are used to determine how data packets are steered. In the banking system, a check comes in and, based on its ABA/FRD (American Banking Association/Federal Reserve District) number, also known as the “routing number,” the bank decides where the check goes next (usually to another bank). On the Internet, a data packet comes in and, based on the Internet address in the packet header, the router decides where the packet goes next (usually to another router). In the banking system, the final decision is which truck a bag of checks should be tossed into. In an Internet router, the “ultimate decision” is the one that determines the I/O port to which the packet should be directed.
The major difference between the Internet and the United States check-clearing system lies in the acquisition of the information on which routing decisions are based. Relationships between banks are essentially static. A “Grand Opening” here or an unexpected bank failure there is a relatively small change, and is managed pretty much manually. And in the banking world, mergers and takeovers don’t “just happen.” They’re planned long in advance and often are heralded widely. In the online world, though, the network is constantly changing, with no fanfare at all. The beauty of the Internet is that it makes adjustments — automatically and continuously — that the banking system just couldn’t handle.
Another difference between the banking system and the Internet is that every bundle of checks has to be accompanied by a “cash letter” that indicates the dollar value of each check in the bundle. In the Internet, as implemented in the United States, there is no accounting of any kind. That’s not true in some other countries, where information transfers are billed by the kilo-packet. In such cases, “least-cost routing” has a real monetary value, and mistakes can cost someone a bundle.
The Internet’s paramount feature — flexibility — also makes it fast. For instance, if a courier company’s truck is full, banks and the Fed won’t ship a bag of checks on a different truck on a different route. Instead, the bag waits for the next truck on the usual route. In contrast, many Internet routers don’t “wait for the next truck.” Instead, they divert data packets to paths that are open (albeit sometimes basing that decision on the cost of the alternate paths, in terms of time or reliability).
This dynamic routing — with parts of a message being forwarded over different and sometimes wildly divergent routes — can cause packets in a TCP stream, or fragments of a UDP packet, to arrive at their destination in wildly scrambled order. Putting packets (and sometimes fragments of packets) back into their original, comprehensible order takes time and computational effort. But, this effort is a small price to pay for coherent messages, even if some packets have to make detours, sometimes in rattly decrepit trucks over dusty back roads, to avoid fatal obstacles.
(This matter of packet reassembly comes up again, with renewed significance, in connection with the IPv4 and TCP protocols, as you’ll see in the sections describing them.)
Comments,
suggestions, and error reports are welcome.
Send them to:
ipstacks (at) satchell (dot) net
Copyright
© 2022 Stephen Satchell, Reno NV USA