Linux IP Stacks Commentary Web Edition
TCP: Transmission Control Protocol
As the Web edition of this book was “in the typewriter”, RFC 9293 was released by the IETF. As the authors digest this new recapitulation of the TCP standard, information in this section will be updated “on the fly”. Check back frequently for those changes
Table of Contents
RFC 793 — (obsolete)
RFC 879 — (obsolete)
RFC 1122 — Requirements for Internet Hosts -- Communication Layers Section 4.2
RFC 2873 -- (obsolete)
RFC 4727 — Experimental Values in IPv4, IPv6, ICMPv4, ICMPv6, UDP, and TCP Headers Secion 7
RFC 4782 — Quick-Start for TCP and IP Section 4
RFC 5961 -- Improving TCP's Robustness to Blind In-Window Attacks
RFC 6093 — (obsolete)
RFC 6429.—.(obsolete)
RFC 6528 — (obsolete)
RFC 6691 — (obsolete)
RFC 7413 -- TCP Fast Open (experimental)
This section brings us to the heart of the matter: Transmission Control Protocol, or TCP.
When
C function names and
certain command names appear
in the text, the parenthesized number indicate the manual section in
which the function is described. This
is consistent with Unix standard documentation. For
example, read(2)
indicates you can use the command
man
2 read
to
read the man page online
that describes
the function.
In the section UDP, you saw how UDP treats data transfer as an occasional, ad-hoc, as-needed event. In contrast, TCP treats data transfer as a continuous bidirectional stream of bytes that are exchanged between two systems. In further contrast, whereas UDP transfers are measured in seconds, TCP connections can stay open for minutes or even hours. Put another way, when faced with the task of moving messages from one side of a river to the other, UDP hires an individual boat and ferryman for each message, while TCP throws down a pontoon bridge and waves the traffic across.
Applications that use TCP range from telnet(1) (a relatively simple network teletype program) to World Wide Web browsers like Edge and Firefox and lynx(1), router-to-router protocols, file transfer programs such as ftp(1), and PC remote-control applications. And much, much more.
These prepackaged applications aren’t the only ones that like TCP. The protocol has also received a warm welcome from certain packages, such as netpipes(1) that offers TCP connectivity in shell scripts. Here, a bit of background is in order.
A simple but powerful concept implemented in Linux involves the use of a facility called pipes, which links the output of one program to the input of another program that is running on the same system. This way, large and useful systems of applications can be built and strings of programs can be assembled into a larger program — in much the same way that individual pop-beads are snapped together by a child to form a bracelet or necklace. In other words, simple modular building blocks are combined to form a single program that performs complex operations.
Back to the netpipes(1) package. A favorite of Linux programmers, it extends the concept of pipes to processes that are running on separate computers and that are connected via a network, so that multiple machines can participate in “piped” command lines.
This technique is often used in conjunction with the tar(1) utility to move entire file systems from one computer to another. In such a transfer, the only place an intermediate copy needs to exist is on the network. Bringing matters full circle, the netpipes(1) package components make extensive use of TCP.
netpipes(1) isn’t installed? No worries. Many system admins use the ssh(1) command and companion sftp(1) programs to perform the same task. Guess what? The secure shell package use TCP, too.
Applications programmers like TCP because it lets “the system” takes care of error detection and error recovery, allowing grateful programmers to pay more attention to the details of the code they’re writing. Yep, programmers do so hate to “reinvent the wheel”.
Why are error-control algorithms so unpopular? Well, because they’re complex, tricky, and downright nasty to do right — especially when different implementations of a given error-control algorithm are supposed to work with each other. The early days of TCP’s development were punctuated by several “TCP bake-offs” (see RFC 1025), at which everyone would try to get their homegrown error-control algorithms to play nicely together (“bake-offs” would be echoed later in the “plug-fests” held regularly by the implementers of the Point-To-Point Protocol). When error control was developed as a system service, these pesky interactions were resolved once and for all, and the sighs of relieved code mavens were heard all ’round the Internet.
Coders of applications like using TCP. It limits the opportunities for mistakes to be made in error control. Additionally, TCP gives them faster and more reliable access to complex applications by making those programs faster to write and easier to maintain. In other words, they don’t have to think about error control. All in all, TCP is a palpable hit.
Because TCP is a system service, it uses the standard system interfaces. As you saw in the section SocketsAPI, the application program interface (API) for TCP uses exactly the same I/O system calls that are used for disk files, serial ports, pipes: the read(2) and write(2) system calls. The differences lie in how the “files” are opened.
Disk files, pipes with specific names, and ports are all associated with file descriptors by means of the open(2) system call. Unnamed pipes are created by means of the pipe(2) and pipe2(2) system calls.
Applications that use TCP socket connections use the system calls bind(2), connect(2), listen(2), and accept(2). After a socket connection has been established between peer programs, the data stream on a TCP connection works exactly like a FIFO queue for data in each direction. In other words, it works exactly the same way as a pipe.
The TCP scheme works so well that it’s common for a process that is running on a given computer to talk to another process on the same computer, but to use the loopback networking interface (“127.0.0.1” for IPv4, “::1” for IPv6) to do so. This way, the application doesn’t have to know that its peer lives in the memory block right next door, instead of across the ocean.
The API for servers is straightforward.
The server program makes a bind(2) system call to register a listening socket with the system, specifying the IP address and the TCP port number for which to listen for connections.
The listen(2) system call blocks execution until a connection request has been received for the socket. [There is a way to do this without blocking using the select(2) and poll(2) system calls, which is outside the scope of this section.]
The accept(2) system call signals the server’s willingness to complete the connection and begin communication.
The read(2) and write(2) systems calls actually transfer data.
The shutdown(2) system call can be used to terminate one half of the connection (for instance, to indicate that all of the available data has been transmitted).
Finally, the close(2) system call breaks the connection.
Here is a code fragment from a real server application written by your humble authors:
if((op ="socket", (g.well_known_socket = socket(AF_INET, SOCK_STREAM, 0)) >=0)
&& (op = "setsockopt", setsockopt(g.well_known_socket, SOL_SOCKET, SO_REUSEADDR, &yes, sizeof(int)) != -1)
&& (op = "bind", (r = bind(g.well_known_socket, PIN(&s_in), sizeof(s_in)) ) != -1)
&& (op = "listen", (r = listen(g.well_known_socket, 0)) != -1)
)
{
printf("Server started on port %d\n", g.port_number);
}
else
{
printf("Server startup failed at
\"%s\"\n", op);
}
When a request comes in (as signaled by the select(2) system call that is used when a connection is being awaited), the server then issues the call to the accept system function.
The API is even simpler for the client program.
By making a bind(2) system call, the client program creates a socket over which to establish a connection.
The connect(2) system call completes the connection. After the connect(2) system call succeeds,
the client uses the read(2), write(2), and shutdown(2) system calls to send, receive, and signal the exhaustion of data.
[The purpose of the close(2) system call is left as an exercise for the reader.]
To show this simplicity in an actual program written by the authors, we present for your consideration this little block of code:
if((op ="socket", (g.working_socket = socket(AF_INET, SOCK_STREAM, 0)) >=0)
&& (op = "bind", (r = bind(g.working_socket, PIN(&s_in), sizeof(s_in))) != -1)
&& (op = "connect", (r = connect(g.working_socket, PIN(&remote_in), sizeof(remote_in))) != -1)
)
{
printf("Connected\n");
}
else
{
printf("Connection failed at \"%s\"\n", op);
}
From the network’s point of view, the life of a TCP connection has five distinct stages:
The two processes (which may reside on two different systems — even two different continents — or on the same system) have not yet connected.
The processes negotiate the opening of the TCP connection.
The processes exchange data.
Both ends signal that they are through transferring data; any remaining dregs of data are discarded, and the connection is torn down.
All traces of the connection cease to exist, bringing us full circle.
A typical TCP connection establishment consists of a TCP SYN packet, a TCP SYN-ACK packet, and a TCP ACK packet. (In a simultaneous open, two processes can start to establish a connection at the same time. TCP is designed to handle this case; and when it does so, it creates a single connection. This situation differs from the equivalent ISO function, in which two connections would be established.) This “ready, set, go!” three-way handshake performs three tasks: it synchronizes the control counters that are used to control data transfer; it exchanges some negotiated options between the two systems; and it opens the transmission paths between the processes.
After the transmission paths has been opened, the TCP connection becomes a full-duplex connection, in which data is transferred in both directions at the same time.
Next, the data is moved. In early communications systems, one end of the connection sent the data, the other end checked it and told the sender that all was well, and only then did the sender send the next batch of bytes. Under this arrangement, the data-transfer rate was limited by the transmission speed of the line and by the propagation delay over the communications channel. The technical term is half-duplex transmission.
Speaking of propagation delay: the late U. S. Navy Admiral Grace Hopper (a. k. a. “Grandma COBOL”) would, during her lectures, hold up a foot-long piece of extruded copper that she called her “nanosecond of wire,” so that the audience could put this abstract slice of time into concrete terms. (A nanosecond is 1x10-9 seconds, or a thousandth of a microsecond.) Now consider a “wire” 15,840,000 feet long, or approximately the line-of-sight distance from Nantucket, Massachusetts to San Diego, California. Light in a vacuum would require about 16 milliseconds (16x10-3 seconds) to travel that distance. In a piece of wire, the speed of electrical signaling is a fraction of the speed of light, so an electrical impulse requires a bit longer to reach from one end to another — roughly 20 percent longer in high-speed communications cable — which means that the signaling time for our coast-to-coast cable is about 20 milliseconds. (In the real network, repeaters on the wireline would impose addition delays, so that the actual coast-to-coast transmission time is 30 milliseconds, but that’s really getting into the weeds.)
During their research into optical computers, scientists at Bell Labs discovered that, because of the propagation-delay principle, a sufficiently long high-data-rate fiber optic cable can be used as a surprisingly large storage medium, even to the point of allowing information about telephone calls to be stored on the same medium that is carrying the calls.
The laws of physics and repeaters aren’t the only sources of delay. The collision avoidance algorithm on an Ethernet can introduce delays when its exponential back-off method (which is used to deconflict frame collisions) goes to work. These delays may be as brief as 100 microseconds for a lightly loaded network, or as long as 30 milliseconds, or more, for a moderately loaded Ethernet. Add to that the time it takes to obtain a time slot, and a period of hundreds of milliseconds — or longer — may elapse before a packet is actually sent on its way. (Of course, if these delays happen often, your network administrator should be thinking about segmenting the Ethernet or moving to faster media, but until such a change is made, you’ll have to live with what you have.)
Finally, very few coast-to-coast connections consist of a single long hop from source to destination. Instead, the connection is made over a series of links connected together by routers. These routers are store-and-forward devices, which means that they have to receive the packet completely, and then figure out where they go next before the packet can be sent on its way. Busy routers usually have a line of packets waiting to board the next-hop link. Each router can introduce between 1 and 250 milliseconds of delay for our packets. (Complex router nests, such as those run by backbone providers, are knit together via Ethernet, too, so that source of delay rears its unlovely head again.)
Back now to TCP data transfers and how to make them fast. The lock-step transfer of data we described earlier works well when the connection is short and direct. When the wire gets longer, or complicated, or congested, the transmission must be uncoupled from the acknowledgment of data, so that data can be sent fast — even in the face of long real time transfer delays. The classic technique (which TCP uses) is called windowing. In this technique, the receiving system guarantees that it can handle a certain amount of data that is sent from the other end. The sending system can then “fill the window” and wait for a response from the receiving system. When the receiving system has processed the received data, it then sends as part of its acknowledgment a window advertisement saying that it can accept more data.
In the early days of TCP, the size of that window was limited to 65,535 bytes. With the growth of faster and faster communications systems — and with no repeal of the law of the speed of light currently in sight — systems now have the ability to negotiate larger windows by using the TCP window scale option, to increase the amount of data that can be “in the pipe.” When the two processes specify this option and provide the buffer space, the maximum size of the TCP window increases from 65,535 bytes to as much as 1,073,725,440 bytes.
Okay, you’ve transmitted the data. When one side has finished transmitting data, it can then shut down that direction by sending a FIN packet. This indicates to the other end that, after it has processed the data it has received, there will be no more. This is particularly important when TCP is used to emulate a Unix pipe — it’s the only way to signal end-of-file to the remote end when the applications don’t have their own in-band signaling mechanism in place.
Each half of the connection can be closed independently of the other direction by the applications (this is how processes signal that the end of a stream of data has been reached). When both directions have been closed, the TCP connection itself is considered closed, and the resources for the connection are released and returned to the operating system. Applications tell the system to send the FIN packets with the shutdown(2) command; on the receiving side, the application sees a zero-length amount of data, which says “That’s all, folks!”
When both sides have sent FIN packets, then the programs see end-of-file, and respond by closing the connection; the kernel removes the socket information from the kernel tables.
Open, transfer, close — sounds simple, doesn’t it? The drudge, as you may suspect, is in the details, and TCP is no different in that regard than in any other enterprise. The complexity, though, is intended to refine and smooth the flow of data through the network, and to make TCP a good network neighbor in how it uses resources. These refinements, ranging from esoteric applications of queuing theory to some basic common-sense optimizations, carry such names as “slow-start” and the “Nagle algorithm.” These optimizations will be described as we go along — and you won’t need a math degree to understand them.
Alas, not every system is a good neighbor. Just as a malicious programmer can abuse the features of IPv4, ICMP, and UDP, so can TCP be abused. The associated commentary for this section points out some common tricks and swindles, and explains how the Linux implementation protects its system from would-be nefarious ill-wishers. The section Firewall Support goes into further detail about how Linux protects itself (and you), including descriptions of the TCP-specific features built into the Linux firewall support.
Now, it’s time to take a closer look at the issues the code has to contend with during the phases of the lifetime of a TCP connection. Bring out the chess board, and let the little game of “data, data, who has the data” begin.
“‘Begin at the beginning,’ the King said gravely, ‘and go on till you come to the end; then stop.’” Wise advice from Alice’s Adventures in Wonderland. But, before you can begin, you have to fall down the...er, establish a path so that communications can take place. The issue before us right now is the establishment, or opening, of the connection.
The job seems simple: exchange a few pleasantries, establish a few ground rules, and start exchanging data. The job is simple, when all goes right (as it does the vast majority of the time). But, this is the Internet, where anything can — and does — happen.
Let’s review the basic job of opening a connection. The typical TCP connection establishment consists of a TCP SYN packet, a TCP SYN-ACK packet, and a TCP ACK packet, a “ready, set, go!” three-way handshake. Call the requester “A” and the requestee “B.”
The first packet, which is the SYN packet sent by A, provides the sequencing information for the A-to-B data direction.
The second packet, the SYN-ACK packet sent by B, acknowledges the setting of the sequencing information in the A-to-B data direction, and at the same time provides the sequencing information in the B-to-A data direction.
The third packet, the ACK packet sent by A, acknowledges the setting of the B-to-A sequencing information.
At this point, both sides of the connection have identical copies of the two (independent) sequence numbers, and agree to any options that may have piggy-backed on the packets that set the sequence numbers.
This agreement means that data can now be transferred. Time to move on and transmit data.
But wait! Right off the bat, a nasty bit of business needs to be addressed. What happens when the second or third packet does not arrive? According to the TCP rules, when something should happen and it doesn’t, you send something to let the other end know that you’re confused. During the connection establishment sequence, the usual thing is to repeat, once or twice, the last packet that you sent. If you don’t see an answer, you abandon the connection attempt as hopeless.
However, this approach has its consequences. During the opening process, the two systems have to create some control structures that may end up being useless, and that will therefore have to be released after a timer has expired. Different systems do different things, so the cost of missteps varies from one TCP implementation to another.
Regardless of the cost, this need to consume resources can be used to launch a denial-of-service attack. Consider the following scenario. Someone says to you “Where shall we have lunch?” You reply with the name of the restaurant and, with the expectation that lunch will be consumed there, you pack up to go to lunch. You wait for a “Let’s go!” but you hear nothing. Indeed, when you look around, a lot of people are standing about waiting to go to lunch, but the person who made the query is nowhere to be seen. Pretty soon, everyone is standing about and no one is doing anything else. This is the essence of a SYN flood attack. An attacker sends the “ready” part (SYN packet) of the open exchange, in large numbers. The system being attacked responds to every single one of these connection bids with the “set” part (SYN-ACK packet) of the message, and also allocates the necessary control structures. The attacker never answers the second packet because it’s being nasty.
Linux implements several layers of defense against this sort of bad behavior. The most obvious tactic is to limit the number of incomplete connections — particularly connections from a specific IP address — so that a digital delinquent can’t (either by design or through stupidity) consume all the TCP connection slots. Another defensive tactic is to limit the lifetime of incomplete connections to a reasonable amount of time, on the theory that if the local system doesn’t hear from the remote system by the time the alarm goes off, it probably won’t hear from it at all. Other, more active, defensive measures will be examined in the associated commentary.
Just as the tenor of a chess game can be set by the first move by White, so can the smoothness of data transfer be set by the first packets being sent. A chess master starts out by moving pawns to establish a front position, and moving other pieces later, to project power onto the board. But, if you try to move more powerful pieces too soon, the result is a chaotic position and ultimately a complete mess. And defeat. Try to push too much data onto the network, and the result is no less messy.
Sun-tzu, in The Art of War, put it more simply: “On the ground of intersecting highways, join hands with your allies.” The metaphorical implications of this maxim as it relates to the Internet are considered in the following paragraphs.
When a TCP channel is opened for a file transfer (such as an FTP file transfer or a Web page download), the startup surge from the newly initiated transfer could swamp the ability of the channel to carry data, and thereby destabilize the links involved, affecting not only the transfer in question but also other transfers that are already in progress.
It’s easy to visualize why this happens. Picture a major controlled-access highway in a metro area during rush hour. An existing stream of traffic is moving as fast as the road allows. Suddenly, a madman roars down an on-ramp and into the traffic flow. The usual result: TV and radio traffic-reporting helicopters converge on the scene to report on the multi-vehicle accident caused by the rude injection of the careening car. The juggern-auto rarely survives, and the collateral damage can be extensive.
Now, electrons don’t bruise that easily, and packets don’t require trips to the body shop. What happens instead is that when a stream of packets is unleashed at full-tilt-boogie rates, the downstream routers can be overwhelmed to the point that buffers can’t hold the traffic...and packets disappear as they are pushed over the virtual guardrail. The packets that do manage to keep a grip on the road find that they arrive at their destination considerably later than they would have if the reckless jackass system had been more reasonable when it injected traffic into the network.
Indeed, the futility of being overzealous in sending data lies in the resulting delays in the transfer — or, worse, the loss — of that very data. Just as a highway will go into its “brake, accelerator, brake, accelerator, pound your fist upon the dashboard” mode when it has too many cars, so will the Internet have widely varying performance, tending toward crawling, when too many packets are crowding the pipeline.
A solution does exist, though. The slow-start algorithm is the TCP equivalent of the highway metering lights you see on so many California highway on-ramps. At the beginning of a bulk-transfer connection, the TCP transmission algorithm sends a limited amount of data, receives the acknowledgments (ACKs) of the data, and — by performing on-the-fly analysis of the timing of the ACKs — decides when to shift to a faster traffic lane. By accelerating the rate of data transmission gradually, the rate of transfer increases steadily until the full bandwidth possible between the two systems has been reached and can be maintained. As the TCP transfer encounters traffic jams, it taps the brakes and backs off. Then, as traffic conditions warrant, it gradually speeds up.
In the Linux TCP code, the slow-start algorithm uses the concept of a congestion window. This window indicates the amount of data that has been successfully sent in the past without causing any hiccups. As data flows through the circuit with good ACK response times, the software will open this window wider and wider to increase the flow of data. When problems crop up, the window shrinks. When TCP’s analysis suggests that the transfer is going as well as it can, the data rate stops accelerating. This way, the algorithm “hunts” for the best balance between throughput and stability. The servomechanism style of adjusting the transmission rate is tuned to balance reactivity to changes in the network path’s capacity with stability in the rate of flow of the data.
The result of implementing this Type-B behavior is that TCP can get more data through the network on behalf of its client (which makes the client happy). Furthermore, the network itself handles far more data more smoothly (which makes the Internet Highway Patrol — and thus other users — happy).
As the first edition of this book was going to press, the State of Nevada passed a law against aggressive automobile driving. Decades earlier than that, though, the Internet community mandated, in RFC 1122, that TCP implementations observe the slow-start rules.
If only real-world motorists would learn this lesson....
The slow-start algorithm described in the last section smooths the flow of data over the network. The rate of bulk transfer can also be throttled by the remote process not being able to handle the data bytes as fast as the source and the network can deliver them. By using window advertisements, the local system can keep the remote system from overwhelming the local system’s RAM.
When TCP is used by interactive applications such as telnet(1), in which a human or some other slow process is involved in creating data to be sent, another optimization can be sent into the game. This optimization, the Nagle algorithm, tries to reduce the number of packets that are transmitted, doing so by being clever about when packets are transmitted.
Frankly, in telnet(1) the overhead associated with sending a single character (such as when a human is at the keyboard) is atrocious. You need at least 20 bytes for the IP header and at least 20 bytes for the TCP header — all for one measly byte of payload. That’s at best a 40:1 ratio of overhead to useful information! Add the overhead for the ACK packet (which lets the transmitting TCP know that the character was received), and you squander 81 bytes of network bandwidth to send just one lousy character. (At least the telnet(1) package is smart enough to eliminate the need for the receiving system to echo that character; otherwise, you’d be looking at a 160:1 ratio — a sure route to bandwidth banditry.)
The grouping of characters in packets takes advantage of the characteristics displayed by humans at the keyboard. The adept amateur typist can produce about 20 words a minute, or an average of 2 keyboard characters per second. In the distribution of typical keystrokes (especially by victims, er, veterans of high-school typing classes), characters are typed in very quick bursts of three to five. (The rest of the time is spent thinking, reading, or trying to find the backspace key.) For more highly skilled touch-typists, the “bursty” distribution of characters is the same, but the volume of keystrokes (that is, characters) per second is higher.
The Nagle algorithm capitalizes on the bursty nature of human typing by intentionally holding off sending a packet until the packet is “full,” or until the first character in the packet gets painfully old. This frame-forwarding strategy is a lot like highway administrators’ efforts to encourage people to carpool. It works like this: when you receive the first character for a packet, you set a timer for some reasonable amount of time (from 0.1 to 0.5 seconds). If you receive more characters in this window of time, you add the characters to the packet. When the timer dings, you launch the packet with as many characters as you have collected.
Using this system, the Nagle algorithm can easily cut the number of packets to less than half of the original volume. The better the typist, the higher the bandwidth savings. The apparent real-time response of the remote systems isn’t significantly affected, especially if the application knows about and deals with special characters (such as the Enter key) that have special meanings.
The Nagle algorithm isn’t just for humans. Programs generate data in spurts as well, so by combining the spurts, the Nagle algorithm can do a remarkable job of reducing the number of packets and the corresponding overhead. For example, the ls(1) command can output short segments of data as it outputs the file names from a directory. The Nagle algorithm can easily collect the short names and make a full packet out of them, thereby drastically reducing the overhead required to send the list of file names.
The Nagle algorithm is particularly important to people and companies who use certain European data networks. These networks charge their users by the packet (actually, by the kilo-packet). In short, the Nagle algorithm isn’t just for being nice; it saves money too.
Unfortunately, some applications can’t stand to have any delay imposed on transmission. Numeric control equipment, for example, may require that commands be issued at strict intervals (that is, with no distortion in transmission time). Speech over Internet also has real-time requirements so the speech doesn’t stutter. Ditto streaming videos: who likes to have their movie or favorite cat video pause? Certain interactive games require that movements and weapons discharges occur on command: the Nagle algorithm would cause a “hang-fire” condition in those games. Although occasional hang-fires are realistic (ask any veteran ground-pounder), they’re usually not part of the game design. For such applications, the API provides controls to turn off the algorithm. So, it’s up to the application to package data appropriately, to avoid unnecessary overhead in data transmission and excessive charges for the poor user.
The economies enabled by the Nagle algorithm are not limited to reducing the number of data packets sent by the transmitting system. Savings are also achieved through a reduction in the number of ACK packets coming back from the other direction.
Speaking of ACK packets, there are possibilities for savings in traffic (and cost) over and above what the Nagle algorithm provides — and TCP uses these tricks. The design of the protocol allows a single TCP ACK to indicate that virtually any number of data packets — as opposed to just one packet — were received properly. This means that the sending of an ACK packet itself can be delayed so that potentially more than one data packet can be acknowledged in a single 40-byte packet. Even better, the ACK can be combined with data going in the other direction so that instead of sending multiple packets — one containing the ACK information and one containing the data bytes — the sending system can collapse two packets into one.
The urge to conserve ACK packets must be tempered with the need to keep data flowing. The ACK packet services two functions. First, it tells the sending TCP that data has been properly tucked away; and second, it tells the sending TCP that room exists for more data. If you as the receiver send too few ACKs, the transmitter will run into what it thinks is a full-window condition, and the data transfer could be slowed, slowed, or stalled.
The Push feature (not available in Linux release 2.0.34) is used by applications that use TCP to transfer transactions. Push lets the application tell the sending TCP code to send any buffered data right now, and to set the PSH flag in the TCP header of the last packet containing the data. In turn, the PSH flag in the TCP header tells the receiving end’s TCP code to make the data available to the application now instead of later. The purpose of the Push feature is to ensure that all of the data involved in a transaction up to that point is presented, as soon as possible, to the receiving application with a minimum of delay. For example, when telnet(1) sees a line-ending character, it should send that line-ending character via a mechanism that triggers the invocation of the Push feature for that character. The TCP implementation then sends everything, up to and including the end-of-line character, to the remote system.
Instead of implementing the Push feature as an item supported by an application interface, the Linux implementation of TCP does not hold off transmission for long periods of time. Specifically, the use of the PSH flag in TCP packets follows the guidelines established in RFC 1122.
The fact that a chess piece can move in several different directions, sometimes even back and forth between two squares, doesn’t mean that it’s to the player’s advantage to move it that way. Such silly moves can give your opponent an opportunity to improve her position, to the detriment of your own. Each move must be considered, and must significantly advance your cause.
In TCP, lack of attention to simple conditions can lead to unnecessary network congestion: too much work for too little gain. Consider, for example, the Silly Window Syndrome. This condition is caused when a TCP implementation makes tiny adjustments to its window advertisements, and the remote system reacts by sending small amounts of data to fill the window. The result is a huge stream of very-small-payload packets. More bandwidth banditry.
Even worse, inattention to the timing of the transmission of ACK packets can cause a blizzard of these packets. It can even lead to false detection of lost data, if the TCP code sees too many ACK packets. A good rule of thumb, according to RFC 1122, is to send an ACK no later than one-half second after the first packet received, or every 3,000 bytes or so of data, whichever comes first.
What happens if the receiver has advertised a zero-byte window, but then, at a later time, advertises a non-zero-byte window...but the packet containing the advertisement is lost? The original TCP didn’t implement a way to detect the loss of the advertisement of open space, so the connection would “hang.” Here’s how the problem is fixed: every so often, the sending side facing a zero-byte window will send one byte anyway. This action is guaranteed to generate an ACK packet, regardless of the state of the window. If the window is still closed, the ACK packet will show a 0-byte window and the same acknowledgment number as before, indicating that the 1 byte of data that was transmitted was rejected and should be sent again later. If the window opened up and the advertisement was lost, the persistence of the sending system is rewarded with a new window advertisement, and by the fact that the single byte of data was accepted.
When the transmitting TCP receives a signal from the application (via the shutdown(2) or close(2) system function) that there is no more data to send, the TCP code expedites the transmission of any remaining data, setting the PSH and FIN flags in the last packet of the stream. If any of the concluding packets are lost, they may need to be re-transmitted — so don’t forget about them just yet.
When the receiving TCP receives a signal from the remote system that there is no more data to be received, the TCP code takes whatever data that is waiting for the application and makes it available to the application on request. After all the data has been sent and received, an end-of-file indication is returned to the application.
When both sides have indicated that they have exhausted their data sources, the connection is closed.
But that’s not the end of the game. Duplicate packets may still be out there, lost in the clouds — but not so lost that they can’t eventually come home. Like a non-compete clause in a bad employment contract, the connection record lives on, usually for about four minutes (the so-called 2MSL time). During this period, random packets that arrive for transmission via the closed connection (rather like a commuter who dashes to the dock just as the ferry is pulling away) are silently discarded. The delay also ensures that the connection well and truly dies, and that all parties have agreed that the game is indeed over, with no last-ditch saves in the offing. Sore Losers
Some people just can’t seem to end a competitive encounter with good grace. The authors have encountered one particular brand of equipment whose TCP implementation refuses to close a connection “the right way,” thereby causing any future attempted connection with that equipment to fail for the 2MSL time. In such cases, you may just have to break the rules and use the reset facility, “killing” the connection deader than dead — like a properly drowned, stirred, and re-drowned campfire. This approach is highly discouraged...so much so, in fact, that the documented way to do it isn’t even implemented in Linux Release 2.0.34!
The reset option is also handy when both sides of the connection get hopelessly confused. It does happen, albeit not often. It’s like fixing a Windows computer: turn it off and on.
No discussion of TCP would be complete without a brief discussion of RFC 1025. This document describes the “bake-off” that was held in the early days of TCP development, to test multiple implementations of the TCP algorithms against each other. The purpose of such events, which are common in the telecommunications field, is to ensure that the standards are written well enough to give programmers a fighting chance of creating an implementation that will work with other programmers’ implementations.
One of the tests was designed to show what an implementation would do with one particular unusually formed packet, referred to by many names: Kamikaze packet, nasty-gram, Christmas tree packet, or (the authors’ favorite) the Lamp Test packet. (The name “lamp test” comes from the key found on military aircraft, commercial airliners, and 1970s computers, which, when pressed, causes every lamp in the vehicle or system to light. The idea was to detect any burned-out bulbs, so that the operators could be sure that a lamp that was not lit wasn’t simply not working.)
This Lamp Test packet had a TCP header with the URG, PSH (EOL in RFC 1025), SYN, and FIN flags turned on. It also contained data. Any reasonable interpretation of RFC 793 in a data-processing environment would never generate such an unusual packet — clearly, this is an artificial test. (Kind of like setting a message in your code that, if all goes well, you should never see. “ESAD” is a popular one.)
Indeed, if you read RFC 793 closely, you’ll see that the protocol designers inserted special rules into the processing of incoming packets to make the Lamp Test packet “legal.” Removing those special rules has no effect on more common packet streams.
On further reflection by the authors, the Lamp Test packet looks like the “group trigger” command, which is part of the IEEE-488 instrument-bus control specification. This capability could be extremely useful in military applications. This could explain why Berkeley implementations of TCP/IP don’t offer any way to generate such a packet. “What, me wargame?”
Here is the sequence of events, as described in RFC 793, that a TCP implementation goes through when it parses the Lamp Test packet (assuming the packet is directed toward a socket in the LISTEN state):
SYN seen: verify that the sequence number is acceptable (we assume it is), enter SYN-RECEIVED state, and continue processing the packet in the SYN-RECEIVED state.
Even though the window that is advertised is zero (the socket isn’t open yet), accept the packet because the URG flag is set. (Note that the Linux implementation determines a window advertisement early enough to avoid the need for the rule.)
Normally, the SYN bit would be an error, but in Step 1, part of the instruction is to skip the SYN and ACK tests. This is the special rule we talked about before.
In the URG bit checking, the SYN-RECEIVED state is not mentioned as a state in which processing is required, so nothing is done.
The text is discarded because no processing is defined for text processing while in the SYN-RECEIVED state.
Checking the FIN bit, we signal the user that the connection is closing (but, we never signaled the user the connection was open), and we now enter the CLOSE-WAIT state.
We’re done with the packet.
The net result: we have a bogus notification to the nonexistent user that the connection is closing; otherwise, nothing happens except that the connection finally goes into the CLOSE-WAIT state. The data is ignored, technically.
So much for silly games. Can you say “Fool’s Mate?”
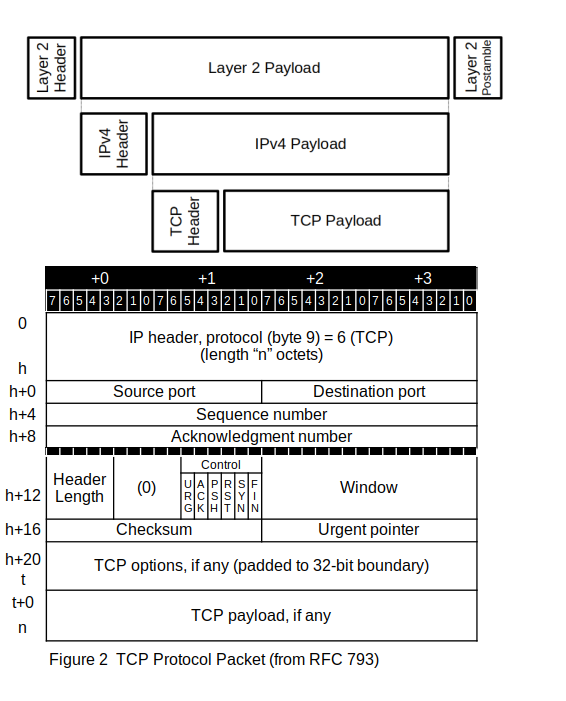
The format for the TCP header is shown in Figure 2.
In the diagram, the value of h can vary from 20 to 60, depending on the IP options that are included in the IP header portion of the packet. The value of t can range from h+20 to h+80, although this high-water mark would never occur with the current definition of the options available. The meaning of each field is:
IP header: the UDP packet is encapsulated in an IP packet, so the packet starts with the IP header — see the section IPv4 for details.
Source port: the 16-bit source port — selected more-or-less at random by the originating system — tells the receiving service where to send any replies. (In the literature, such a randomly-selected port value is referred to as ephemeral.)
Destination port: The 16-bit destination port identifies which service or process should receive this packet. A host, identified by an IP address in the IP header, can have a number of TCP services operating. Table 1 shows some of the well-known TCP service destination ports; a complete list is found at /etc/services on any modern Unix/Linux system.
Destination port |
Service |
20/21 |
FTP (file transfer) |
22 |
SSH (secure shell) |
23 |
TELNET (virtual teletype) |
25 |
SMTP (e-mail) |
80 |
HTTP (web) |
443 |
HTTPS (secure web) |
989/990 |
FTPS (secure file transfer) |
Table 9.1 — Sample of TCP service ports
Sequence number: The 32-bit sequence number of the first data octet in this segment (except when SYN bit is 1). If SYN is 1, the sequence number is the initial sequence number (ISN) and the first data octet is ISN+1. The sequence number field identifies the relative offset from an arbitrary starting point for the first data byte contained in this packet. If no data is contained in this packet, the sequence-number field indicates where the next byte to be sent will be positioned in relation to that arbitrary starting point. Because packets may arrive in something other than their proper order, the sequence number identifies the relative position of the data contained in received packets. The sequence number field ensures that the data bytes can be presented to the applications at the receiving end in the same order in which the applications presented them at the sending end. If more than 232 data bytes are transmitted, this 32-bit sequence-number field will wrap. The sequence numbers are independent in each transmission direction. More on this later
Acknowledgment number: The 32-bit Acknowledgment number lets the receiver tell the sender the last packet sequence number it saw. Also, more on this later
Header length: ranges from 5 to 15. Number of 32-bit words in the TCP header (h+0 to t), which covers the fixed fields and any TCP options.
Control: These six one-bit fields control the transfer. More details about how the control bits are used comes later. The meanings of the individual control bits:
URG |
Urgent Pointer field significant |
ACK |
Acknowledgment field significant |
PSH |
Push Function |
RST |
Reset the connection |
SYN |
Synchronize sequence numbers |
FIN |
No more data from sender |
Window: The 16-bit window field describes the current window advertisement, the amount of data the receiver guarantees to the sender the receiver can receive and store. The value in this field is multiplied by the window scale factor (described later when we describe the options field) to identify the size of the available window. This value may be 0, which tells the sender not to try sending anything. Like the acknowledgment number field, the window field is set by the system that receives the data.
Checksum: The 16-bit checksum field contains a checksum of the information in the TCP header, plus selected information from the IP header, plus the TCP payload. (See RFC 793 — it isn’t bad, but it isn’t simple, either.) RFC 1071 contains very useful information about calculating the checksum, especially about how to do it quickly and how to use assembler code to extract the maximum possible performance from the checksum algorithm.
Urgent pointer: The 16-bit urgent pointer field contains an unsigned positive offset from the sequence number (contained in the sequence-number field) to the sequence number of “urgent” data. This feature is used by several applications to provide a means for signaling interrupt conditions, even when TCP is advertising a zero-window size so that no data can be sent. It is used by some applications to simulate an out-of-band data channel for control data.
The interpretation of the urgent pointer is the “dirtiest” part of TCP. In the original RFC 793, the definition in Section 3.1 says that the offset added to the sequence-number field points past the urgent data. The documentation of the SEND pseudocode function (on page 56 of RFC 793) implies that the offset added to the sequence number field points to the last byte of urgent data. The Berkeley implementations of TCP use the prose definition, while other implementations use the pseudocode definition. RFC 1122 has decreed that the latter interpretation is the “correct” one. That makes interoperation with Berkeley implementations tough. Linux fixes the problem by letting the application decide which interpretation to use. The app selects which interpretation by calling the setsockopt(2) system call with the SO_BSDCOMPAT operation code. See the section socketsAPI for details. (At least the default value for the option is to follow RFC 1122.) It’s too bad that no code in Linux Release 2.0.34 takes advantage of this setsockopt(2) call.
New applications should be coded to assume that the sequence number of the urgent data (sequence-number field plus option field) is the sequence number of the final byte (“octet” if you prefer the RFC language) of the urgent data.
TCP Options: The variable-length options field (which may be completely absent) contains a byte stream of options data. Each option has an 8-bit kind field. If the option carries data, there is an 8-bit length field, followed by (length – 2) octets. If the options do not end on a 32-bit boundary, add NOP codes until it does. The options are:
00000000 |
Eight-bit value zero marks the end of the TCP options list.
00000001 |
Eight-bit value of one (1) indicates a no-operation (NOP). This is used in some implementations to pad out an option to a 32-bit boundary.
00000002 |
Length (4) |
16-bit maximum segment size |
Eight-bit value of two (2), plus 8-bit length, plus 16-bit value for maximum segment size in octets.
00000003 |
Length (3) |
8-bit window scale factor |
Eight-bit value of three (3), plus 8-bit length, plus the 8-bit value for window scale (left shift) .
00000008 |
Length (10) |
32-bit timestamp |
32-bit timestamp reply |
Eight-bit value of two (2), plus 8-bit length of ten (1), plus 32-bit timestamp, plus 32-bit timestamp reply (see RFC 1323).
Table 9.1 The TCP packet header options.
The maximum segment size (MSS) option overrides the default segment size for the purposes of performing the slow-start algorithm. The default is based on the path maximum transmission unit (MTU), and is calculated during MTU discovery, if discovery is needed.
The window scale factor contains the number of bits the window field should be shifted when calculating the number of bytes that can be transmitted. This value may range from 0, the default, to 14, which allows a 1GB window advertisement.
The timestamp option is analogous to the timestamp option in IPv4, except that it measures the interval only between the two TCP implementations; no router gets involved as with the IP option. RFC 1323 contains more information on how this timestamp value can be used, and some of the pitfalls in doing so.
The timestamp is considerably more valuable when used in conjunction with very-high-data-rate connections, as an extension to the sequence number to protect against the 32-bit sequence number wrapping too quickly. This is called PAWS (Protection Against Wrapped Sequence numbers). Because the channel can handle data so fast, the added overhead of carrying the sequence number is well worth the protection against too-early reuse of sequence numbers. (This problem won’t turn into a monster until your systems are connected to gigabit-capacity fiber optic lines with significant end-to-end delays, which have become available.)
Other options have been defined, so the above table will grow over time. As of Linux 2.0.34, though, 0,1 shows a complete-enough list. Indeed, the MSS option is the only one that Release 2.0.34 supports.
As with IP options, any empty space in the options field needs to be filled with padding characters, so that the options fit evenly into one or more 32-bit words.
You might ask how the computer knows how long the packet is, and whether any data at all is in the payload of the TCP packet. The answer is that the length of the TCP header, h+0 to t, is in the TCP header itself, and the length of the IP packet payload, h+0 to n, are included in the IP header. Calculating the size of the TCP payload is simple arithmetic, after all.
Comments,
suggestions, and error reports are welcome.
Send them to:
ipstacks (at) satchell (dot) net
Copyright
© 2022 Stephen Satchell, Reno NV USA