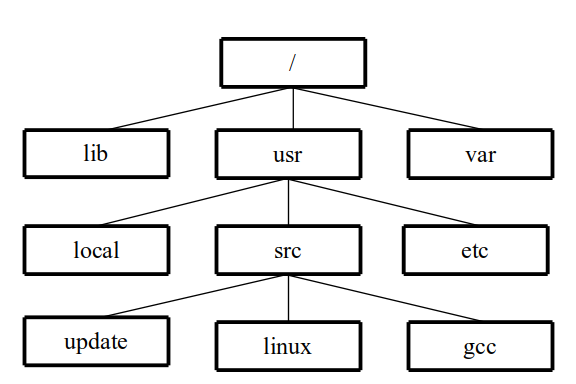
Figure 1 File name tree for /usr/src/linux.
Linux IP Stacks Commentary Web Edition
DNS: Domain Name Service
RFC 1123 — Requirements for Internet Hosts -- Application and Support Section 6.1
RFC 4035 — Protocol Modifications for the DNS Security Extensions
RFC 4343 — Domain Name System (DNS) Case Insensitivity Clarification
RFC 4648 — Measures for Making DNS More Resilient against Forged Answers
RFC 5452 — Measures for Making DNS More Resilient against Forged Answers
RFC 7413 — TCP Fast Open (experimental)
RFC 7766 — DNS Transport over TCP - Implementation Requirements
RFC 7858 — Specification for DNS over Transport Layer Security
RFC 8310 — Usage Profiles for DNS over TLS and DNS over DTLS
RFC 8446 — The Transport Layer Security (TLS) Protocol Version 1.3
RFC 9210 — DNS Transport over TCP - Operational Requirements
This section describes one outstanding example of how UDP is used in day-to-day network communications, the Domain Name Service. In the section UDP, you learned about the User Datagram Protocol (UDP) and saw how its connections differ from standard TCP connections.
When
C function names appear in the text, the parenthesized number
indicate the manual section in which the function is described. This
is consistent with Unix standard documentation. For example, read(2)
indicates you can use the command
man
2 read
to read the
man page online
that describes the
function.
Before we can get into the nitty-gritty bits-n-bytes, we need to introduce to the the concepts of the Domain Name Service.
In virtually every network application that’s written for use by human beings, host names (more commonly “hostnames”) have to be converted to Internet addresses. This task is so common and so pervasive that you’d expect it to be a built-in part of the great networking universe.
Not so. One of the guiding rules of the Zen of Unix is: “do one thing, and do it well.” The Linux corollary is to: “keep as many functions as possible out of the kernel code; leave those tasks to the library lookup functions incorporated into applications or to separately maintained daemons.”
(If you want to skip the history and theory, advance to “The Look-It-Up Club” subhead.)
In the dark history of Unix et al and the Internet, the conversion from a human-readable name to an address was in a host table file, distributed from a well-known source or included in software installation packages. In Linux, the file /etc/hosts is still used to define names that identify the local machine. From the author’s computer running Ubuntu:
/etc/hosts:
127.0.0.1 localhost
127.0.1.1 game
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost
ip6-loopback
fe00::0 ip6-localnet
ff00::0
ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
Imagine a file hundreds of lines long, with all the associations. Associations that change on an irregular, but frequent, schedule. Now scale that up to millions of domain names. Horrible.
When human beings look up information, they tend not to think in terms of long strings of numbers or hexidecimal digits. Instead, they think in terms of www.mit.edu, ftp.linux.org, or news.uu.net. Consequently, one way or another, every single application that involves people uses names rather than numbers to identify services. Humans, meanwhile, rely on software applications that let computers do what computers do best — namely, the bookkeeping.
And what a bookkeeping task it is. Millions of names are currently in use for the “com” domain alone. Add the other domains (org, edu, net, and the rest), and the number of endpoints is mind-boggling. A printed list would be larger than the New York City phone directories for all the five boroughs...and would be obsolete the instant it hit your porch.
A centralized online database would be just as obsolete, but even sooner. Worse still, the database would be prone to single-point failures, and the number of lookup operations that would have to be performed in response to inquiries from around the world would run to millions per second. How can such a workload be handled? The answer echoes the guiding principle of the Internet itself: distribute the task.
Several different namespace management systems were devised during the development of the Internet. What was needed was a distributed database of structured names, with an army of administrators maintaining the data for each domain under their control.
Thus was born the Domain Name System (DNS, sometimes referred to as the Domain Name Service), which was first implemented in 1985 in the Berkeley Internet Name Domain (BIND) software package. “The DNS” is essentially a distributed database of hostnames, in which the names are organized in the form of tree structures.
Put simply, DNS simply distributes name information among many servers, using almost the same method that Internet Protocol routers use when they distribute information about the structure of the network: that is, neighbors talking to neighbors.
Almost, but not quite. To understand the difference, you need to get acquainted with the structure of a domain name, and then see how domain names relate to the rest of the network. For a more extensive description, see Paul Albitz and Cricket Liu’s excellent book DNS and BIND (5th ed., O’Reilly & Associates, May 2006; ISBN 0-596-10057-4).
Just as Unix has “directories” and Windows or Macintosh systems have “folders,” DNS has “domains.” A domain name, which defines the path through the DNS name tree, consists of several labels, separated by a period (.). A fully qualified domain name (FQDN), such as “berkeley.edu.” — note the period at the end of the string — defines an absolute name. Domain names can also be relative, just as a file name can be relative to the current directory or folder. Relative domain names don’t have a period at the end.
A domain name can have any number of labels, and any label can appear in two or more domains. For example, the domains “berkeley.edu.” and “berkeley.org.” refer to two separate domains, in just the same way that file systems allow /foo/bar and /heath/bar to refer unambiguously to two separate files.
The concept of domains is an essential part of the rules that govern how domains are managed.
In most OS file systems, each individual file name has the “leaf” of the name tree that appears at the rightmost end of the file name string. In the domain name, each “leaf” appears at the leftmost end of the domain name string.
For instance, the file name /usr/src/linux implies the tree structure shown in Figure 1. The same tree structure would be implied in the Windows file name c:\usr\src\linux or in the Macintosh file name Hard Disk:Usr:Src:Linux. In other words, labels in file names are read and interpreted from left to right, from root to leaf.
Figure
1 File
name tree for /usr/src/linux.
The DNS naming conventions read the labels in the reverse order: from right to left, from leaf to root. The tree structure shown in Figure 2 is implied for the FQDN “ftp.berkeley.edu.”, which contains four labels: ftp, berkeley, edu, and the empty string “”.
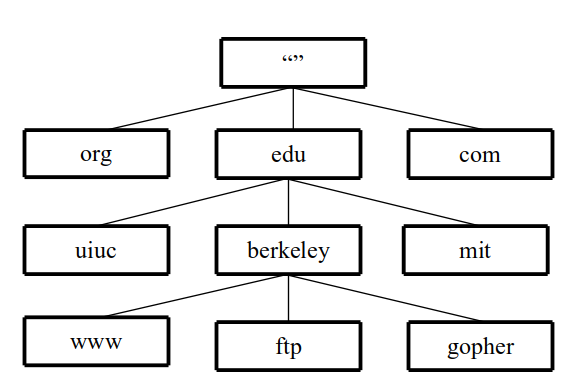
Figure
2
Domain
name tree for ftp.berkeley.edu.
Each domain customarily provides a name for a collection of networks, a collection of systems, or a collection of services on a host. The top-level domains, which consist of the common two-letter country codes (“us.” for the United States, “ru.” for Russia, and so forth) and the three-letter global top-level domains (gTLDs, such as “com.”, “edu.”, and so forth), contain a mixture of network names and host names, with the actual structure of each domain being determined by how management is delegated as you go down the tree.
When you get to the leaf node in a DNS tree, you find that there are a number of pieces of information associated with that node: resource records. For example, you can have IPv4 addresses (“A”), IPv6 addresses (“AAAA”), mail exchanger specifications (MX), name servers (“NS”), and even a way to alias a name to a different part of the DNS tree (“CNAME”). The complete list of Resource Record (RR) types can be found here: IANA document Domain Name System (DNS) Parameters.
At the time this section was written, there were more than 250 difference resource record types, with more being added at a regular pace. Some of the types are experimental; others are for different networking systems like X.25 or CHAOS. In the design of the DNS protocol, the type is a 16-bit number, so there is plenty of room for the list to grow.
Don’t worry, the list of the most common resource record types one encounters with most domains is much smaller.
Earlier, I said that “the Linux Way” is to keep as much as possible out of the kernel. So how does an application program convert names to IP addresses and such?
Enter the resolver — a module or daemon that takes requests and returns information. In C, the library routine is getaddrinfo(2) (replacing the older gethostbyname(2) routine). In shell scripts, one uses the nslookup(1) utility, or if the BIND software is installed the dig(1) utility. For Python, “import socket; socket.gethostbyname” returns a string with the IP or IPv6 address; for leafs with multiple IP addresses, the result returned by socket.gethostbyname is randomly selected from the list. Other compiled and scripting languages have similar library routines or utilities for learning DNS information.
One of the mechanisms that these name resolver library routines and utilities use is to send requests to a DNS server known to the device: sometimes the DNS server address is provided via DHCP exchange, sometimes by specification in a configuration file. As part of its duties, the routine or utility sends queries to servers on the network, packaging those queries as UDP packets (see section UDP), TCP streams, or Web transactions with special servers.
The query function or utility usually doesn’t do all the work; it will instead send requests to a recursive DNS server, that does all the hard work going down the domain tree to fetch information. Say your device picks up the DNS servers to use from a DHCP transaction: that server is better connected than your device, so it can perform the tree search much faster than your phone or laptop can.
So, in its most basic form, DNS is a good example of a broad-based application using UDP, and whose usage stems from the fact that DNS is based not on a client “program” but rather on a set of library functions used by programs, with the library functions doing the actual work.
The contents of this book refer often to 32-bit Internet Protocol addresses, each of which consists of a binary number. The human-readable version of these numeric addresses each consist of four groups of one- to three-digit numbers, like 127.0.0.1; the binary version of an IP address appears several times in every IP packet, and are also used when socket objects manage connections.
With the introduction of IPv6, Internet Protocol addresses grew to 128 bits, with some disagreements on the format of the human-readable version of these huge numbers. In Linux, you will see four-character hexidecimal addresses separated by a colon (:), like “2600:1700:79b0:ddc0::40”, with the double-colon representing a string of binary zeros.
The only difference “inside” is the length of the IP address field and the format used to render the binary to human readable format. The operation of the protocols “above” IPv4 and IPv6 are for the most part unchanged.
As any consultant will tell you, no individual supervisor (boss) can handle dozens, let alone hundreds or thousands, of immediate subordinates (“direct reports”). Instead, authority must be delegated to subordinate supervisors who are closer to the workers. So it is with DNS.
Domains are actually defined on an army of systems, known as name servers, that are known directly or indirectly throughout the Internet. Although each name server originally resided in the domain that it defined, this practice is no longer rigidly followed. Name servers today can also define multiple domains.
Any changes made in a name servers are eventually reflected throughout the Internet, because all the name servers talk to each other, either directly or indirectly. The only place where this procedure isn’t followed is at the top-level domains, where name management is handled via email, via postal mail, or some other use of an API for adding second-level domains to the root servers.
Many delegations (that is, assignments of authority to secondary entities) are set up the same way, such that the contents of the DNS database are handled through the online update paradigm. As a result, management of the databases is so well distributed that no one entity is saddled with the whole task. Even better, the potential for a single-point failure is minimized or even eliminated.
Thanks to distributed maintenance, DNS protocols have access to mechanisms that let them duplicate — periodically and in many locations — the active contents of the DNS database using caching to avoid doing extra work. This periodic duplication means that domain-name requests can be spread over a very large number of name servers, so that failure of a single server — even a failure of the server of the designated DNS database maintainer — doesn’t make names “disappear.”
DNS contains a lot of detailed
information about the endpoints of a network. The most important
piece of information is the so-called A resource
record, which describes
the relationship between the name of a host and its Internet address.
For IPv6, the AAAA
resource record performs the same job. Meanwhile,
the PTR resource record
provides
the name based on the IP address passed in the request.
DNS also can hold information about the host, such as its hardware
and software, and contact information for the system administrator.
(For further
details, see RFCs 974, 1034, 1035, and 2181.)
DNS also stores information that is important to the e-mail systems used by users (or systems). This information is stored in the MX resource record.
If DNS seems to be just too simple, bear in mind that a given network or system can have more than one name, and that a given name can refer to more than one IP address. This multiple-name situation occurs, for example, when a server is known by several aliases. The multiple-address situation occurs when a server is multi-homed (that is, when it is connected to multiple independent networks) and can be reached from each one of those independent networks. In other words, each interface has its own IP address.
Each record in the DNS database has an associated Time to Live (TTL) parameter, which indicates how long a given entry should be assumed to be accurate. In associating a given name with a given address, a DNS server “remembers” an earlier request, so that the request doesn’t have to be repeated each time a client application needs the name. Because this function is part of the system or local network rather than part of the client application, a given name can be used by several applications, and only one query from the system group goes out over the network.
Back to the resolver. In most cases, this subroutine or daemon discovers the IP address of a name server. A system administrator may have specified the name server to use; or, perhaps, DNS server information was provided as part of the automatic process of assigning an IP address using the DHCP protocol.
The resolver sends a name query to that name server, via UDP. The server returns a response to the request. This response includes not only any IP addresses that are associated with the name, but also information about name servers that can return authoritative answers to the inquiring routine. Here, the word “authoritative” means that the answer is provided directly by the system that defines the name. A non-authoritative answer is one that is provided by a cached record, which may have been changed, even if the specified Time to Live hasn’t expired.
In rare instances, the client subroutine is forced to perform an iterative process, looking up name servers for each intermediate domain for the name in question, and ultimately submitting the desired name to the last enclosing domain. This iterative process is usually performed by the upstream name server, on the theory that a server on a broadband link to the Internet is in a better position than the client system to perform the top-down search.
In C, the gethostbyname(3) function (as it pertains to UDP-based queries) takes a domain name (which may be either relative or fully qualified) and submits, to the name server, a request for resolution of the name to an address. After this task has been completed, a list of addresses is returned. The first address in this list is the one most likely to be the “closest” to the system.
gethostbyname(3) has been superseded by getaddrinfo(3).
The gethostbyname(3) function builds a UDP packet that contains the desired name, sends the packet to the name server address contained in the resolver configuration file (usually /etc/resolv.conf in Linux), and waits for a reply. If the server replies that it can’t find information about the name, and if the name in question is a relative name, the function starts appending default domain names to the specified name and repeats the query of the server. It continues this process until it receives a response or until the list of searchable default domains has been exhausted.
Within gethostbyname(3), a temporary UDP connection is established with a name server in the list. The name servers listed in the resolver configuration file are queried, one by one, until one of them responds. Because UDP is a connectionless service, the function cannot send any requests until after it has registered a listening port. After a response has been received (or a timeout has indicated that the server isn’t responding), the listening port must be closed.
The actual packets that are exchanged between the resolver routines and the name servers are described in detail in RFC 1035. RFC 1034 illustrates typical transactions in schematic form. Figure 3 shows the general layout of a packet during the exchange procedure.
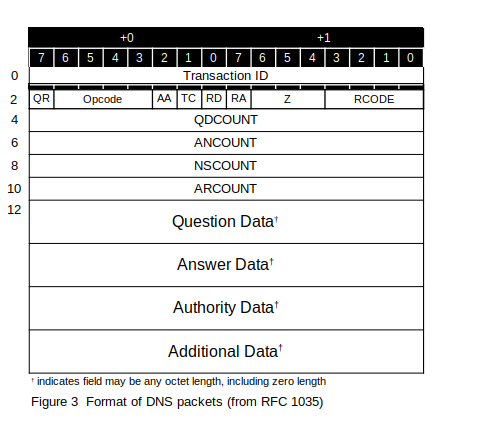
Transaction ID: The 16-bit Transaction ID field contains a 16-bit number used by the requesting program to match requests and responses. This number lets a requester have multiple requests outstanding, and uses this field to send the results to the process that made the request. The mechanics of handling this field is up to the implementer.
QR: The QR bit indicates whether this packet is a query (set to 0) or a response (set to 1).
Opcode: The Opcode field contains a 4-bit value that is 0 for a standard query, 1 for an inverse query, or 2 for a server status request. The values 3 through 15 are reserved.
AA: The AA bit indicates, in response packets, that the name server providing the information is an authority (master) for the domain name in the Question section. In request packets, set to 0.
TC: The TC bit indicates, in response packets, that the message was truncated because it was too long to fit through the transmission channel. (Note: When a requester sees this, it should retry the request using TCP; see below and RFC 1123 et seq.) In request packets, set to 0.
RD: The RD bit indicates, in request packets, that a recursive lookup by the recipient is desired. (Specifically, the name server should initiate multiple queries, if necessary, instead of having the requesting program do so.) This bit is usually set by a resolver in a client system, rather than by a name server that is issuing requests. The RD bit is copied, unchanged, into response packets.
RA: The RA bit indicates, in response packets, whether the name server supports recursive queries. In request packets, set to 0.
Z: The bits in the Z field are reserved. They should be ignored when packets are examined, and set to 0 when packets are built.
RCODE: The RCODE field indicates, in response packets, the results of the query as shown in the following table. For request packets, this field is set to 0.
RCODE value |
Meaning |
0 |
No error |
1 |
Format error |
2 |
Server error (SERVFAIL) |
3 |
Name does not exist (NXDOMAIN) |
4 |
Request not supported |
5 |
Refused for policy reasons (block zone transfers, for example) |
QDCOUNT, Question Data: The original query. In request packets, the 16-bit length in octets that are contained in the question data field is in the QDCOUNT field. In response packets the data is copied from the request packet.
ANCOUNT, Answer Data: The 16-bit length in octets that are contained in the answer data field is in the ANCOUNT field. In request packets, these fields should be set to zero and empty. In response packets, these fields describe the direct answer(s) to the query, if there is one.
NSCOUNT, Authority Data: The 16-bit length in octets that are contained in the authority data field is in the NSCOUNT field. In request packets, these fields should set to zero and empty. In response packets, these fields describe the answer(s) to the query, if there is one. The data from a response usually contains the name servers’ FQDN information
ARCOUNT, Authority Data: The 16-bit length in octets that are contained in the authority data field is in the ARCOUNT field. In request packets, these fields should set to zero and empty. In response packets, this field contains additional information associated with the original query, if there is one. The data from a response usually contains the name servers’ IP address information
The interpretation of the data is contained in RFC 1035 and not elaborated here. Each data field, except the request data, can contain multiple logical records.
Note: The four data fields may be compressed data, see RFC 1035 section 4.1.4 for details.
The authors have written a Python program to read the binary data from a DNS query or response. At the end of the introductory comment is a packet capture [via the tcpdump(1) network command] and a visual breakdown of an actual query and response.
Some of the transaction requests can exceed the length that can be carried over UDP. Transaction answers that will exceed UDP’s message size include zone transfers (AXFR), a perfect example of a request that will generate a great volume of data. The latest information on this type of transfer is found in RFC 9293
For TCP transfers of DNS packets, the packet as shown above is prefixed with a 16-bit octet length of the entire packet (excluding the 16-bit packet length field). (RFC 1035)
(Author note: why didn’t they future-proof the change and use a 32-bit size value instead of a 16-bit one? This may bite us all in the future.)
RFC 7766 also references “TCP Fast Open” (RFC 7413) as a way to shorten the transfer of the initial query, as well as query pipelining so that several requests can be handled over an established TCP connection.
See RFCs 7858, 8094 (experimental), 8310 (standards track)
DNS over TLS (Transport Layer Security) is an extension of DNS over TCP to perform domain name queries and responses over an encrypted channel, or tunnel. Before sending a query, the requester negotiates a TLS connection (RFC 5246). Once the tunnel is established, the requester then follows the same protocol as DNS over TCP, described above, to send a query, and the responder to transmit the reply to the query.
A description of TLS is beyond the scope of this section, but a separate section may be available. There are many articles about how to increase the security of the connections. For example, several articles state that best practice is to use TLS version 1.2 or higher. (Interoperability concerns may require a DNS server to allow older versions in its configuration; DNS clients need to restrict use to version 1.2 unless there is a damn good reason not to.) Ditto selecting the more secure cipher suites over the old, insecure ones.
The TLS service handler on a DNS server, if there is one, uses domain-s (port 853/TCP) to answer queries.
Some public DNS resolvers support DNS over TLS; use a search engine to obtain the most current list. There are also tutorials on how to set up your own DNS-over-TLS server, if you are so inclined and paranoid enough. (The authors haven’t attempted this yet.)
Incomplete description, still researching
Still experimental
Uses port 443
RFC 8484 (standards track)
Uses standard GET and POST methods
In order to properly check out how the various methods work for DoH, I need to write two Python programs: one to build DNS request packets, and one to decode the response from the DoH server. Then use wget to make the transactions. Question: should I make those programs available in the web book?
The request is constructed with a single variable “dns=” followed by the DNS request as shown at the top of this section, encoded in base64url (RFC 4648). The base-64 encoding expands the size of the message.
$ wget -O - --inet4-only \
--header='accept: application/dns+json' \
'https://dns.google.com/resolve?name=www.satchell.net&type=A' \
| jq
{
"Status": 0,
"TC": false,
"RD": true,
"RA": true,
"AD": false,
"CD": false,
"Question": [
{
"name": "www.satchell.net.",
"type": 1
}
],
"Answer": [
{
"name": "www.satchell.net.",
"type": 1,
"TTL": 21553,
"data": "76.209.1.164"
}
]
}
Comments,
suggestions, and error reports are welcome.
Send them to:
ipstacks (at) satchell (dot) net
Copyright
© 2022 Stephen Satchell, Reno NV USA